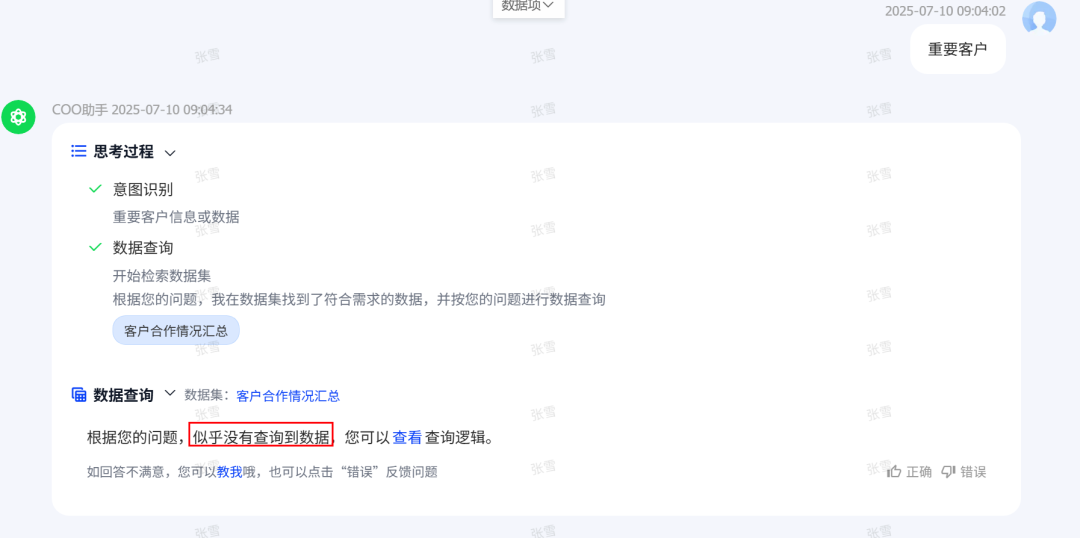
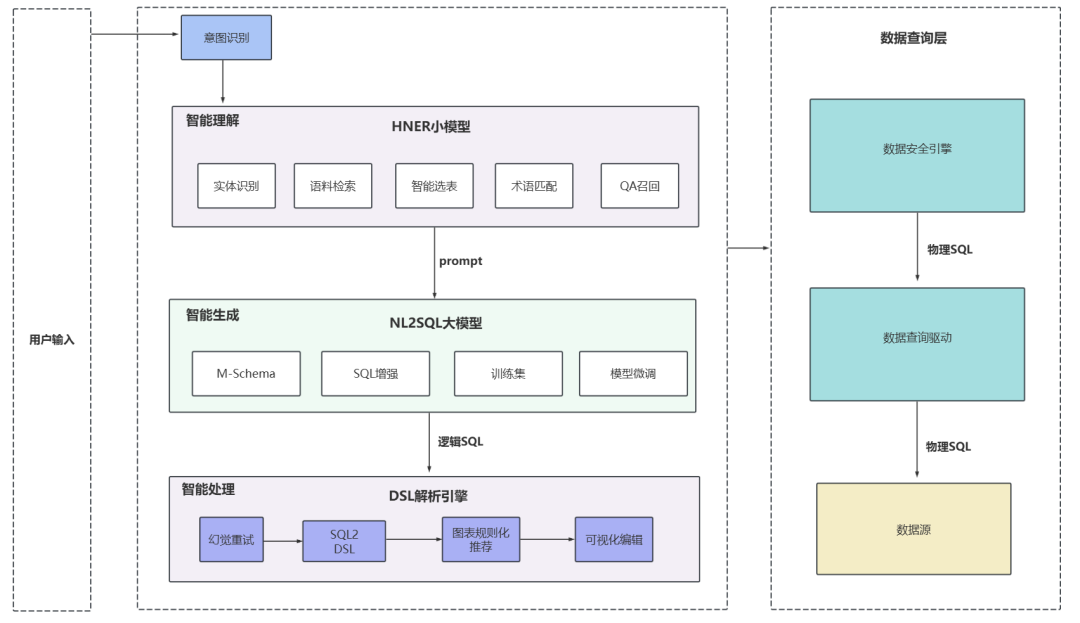
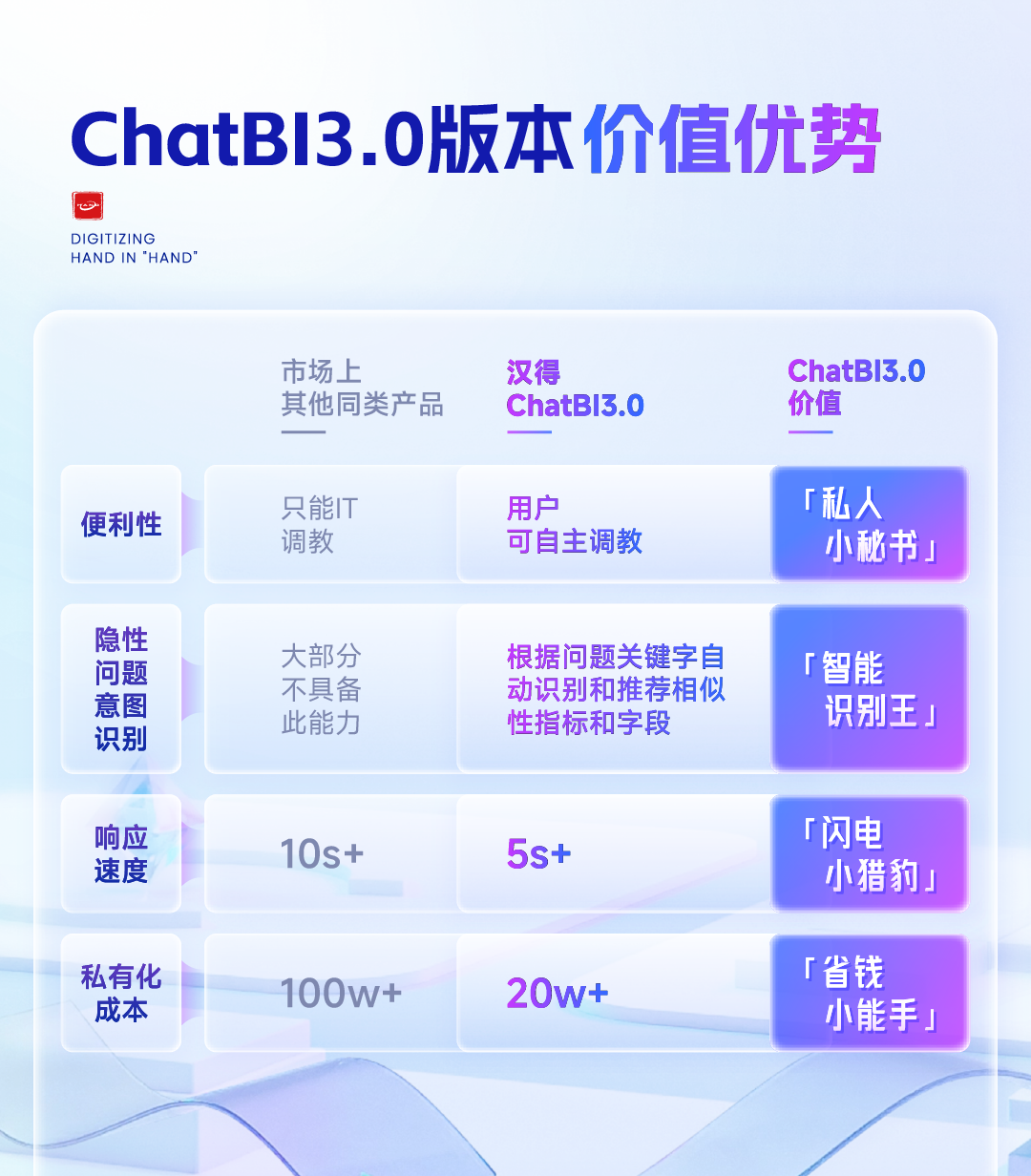
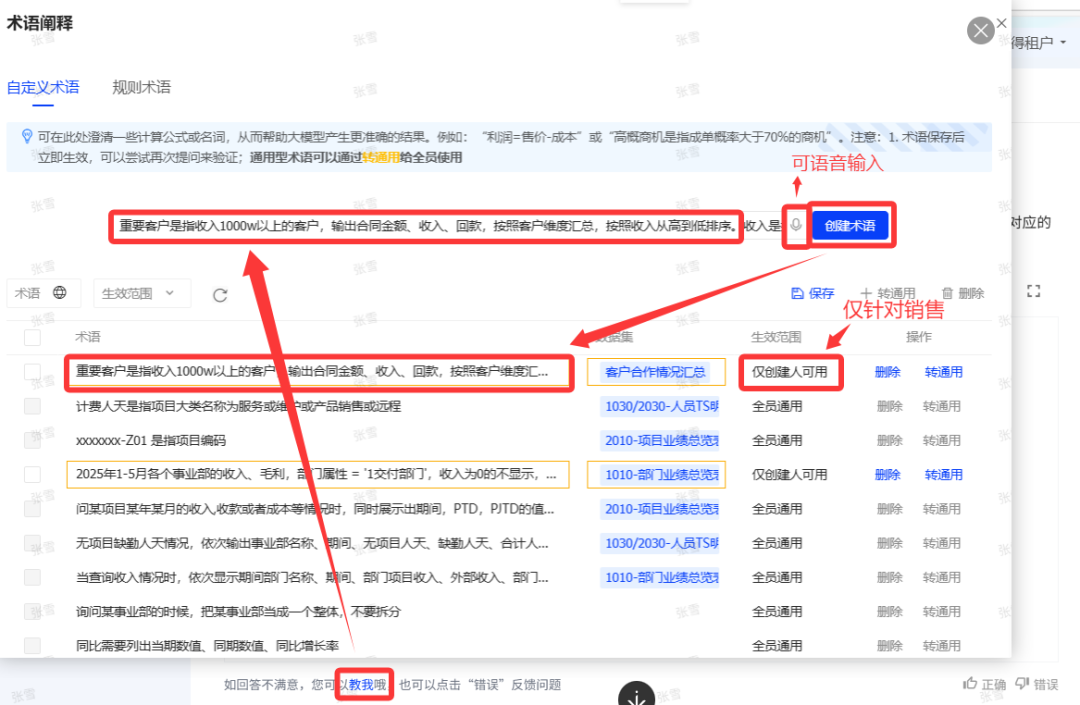
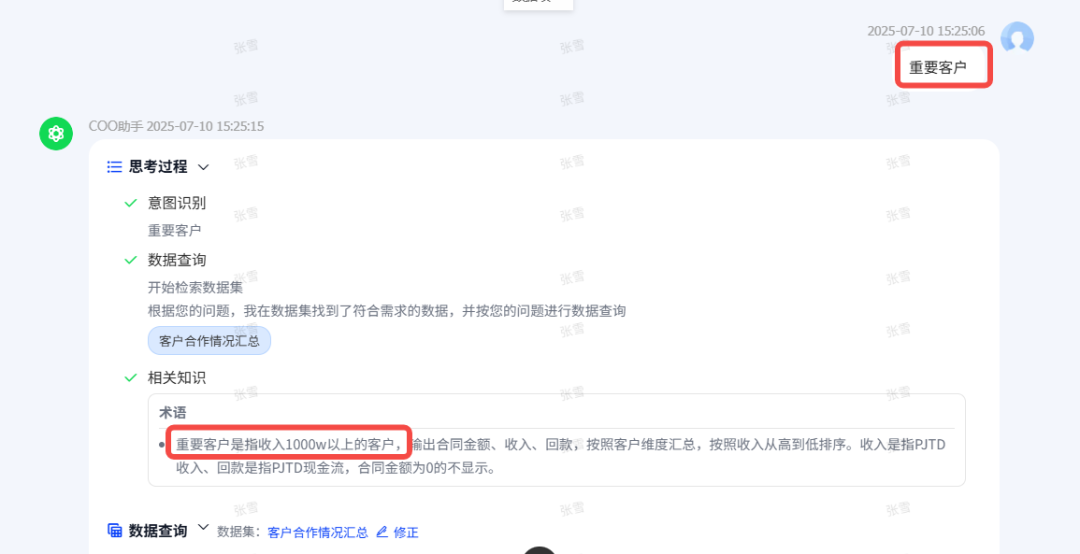
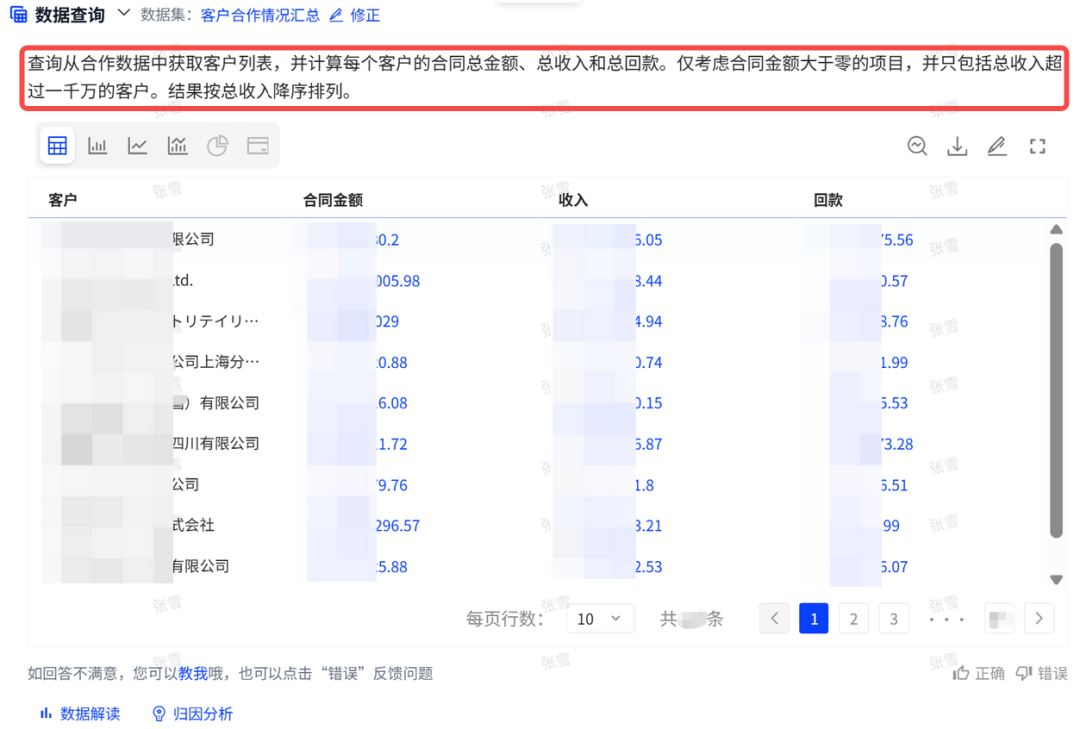
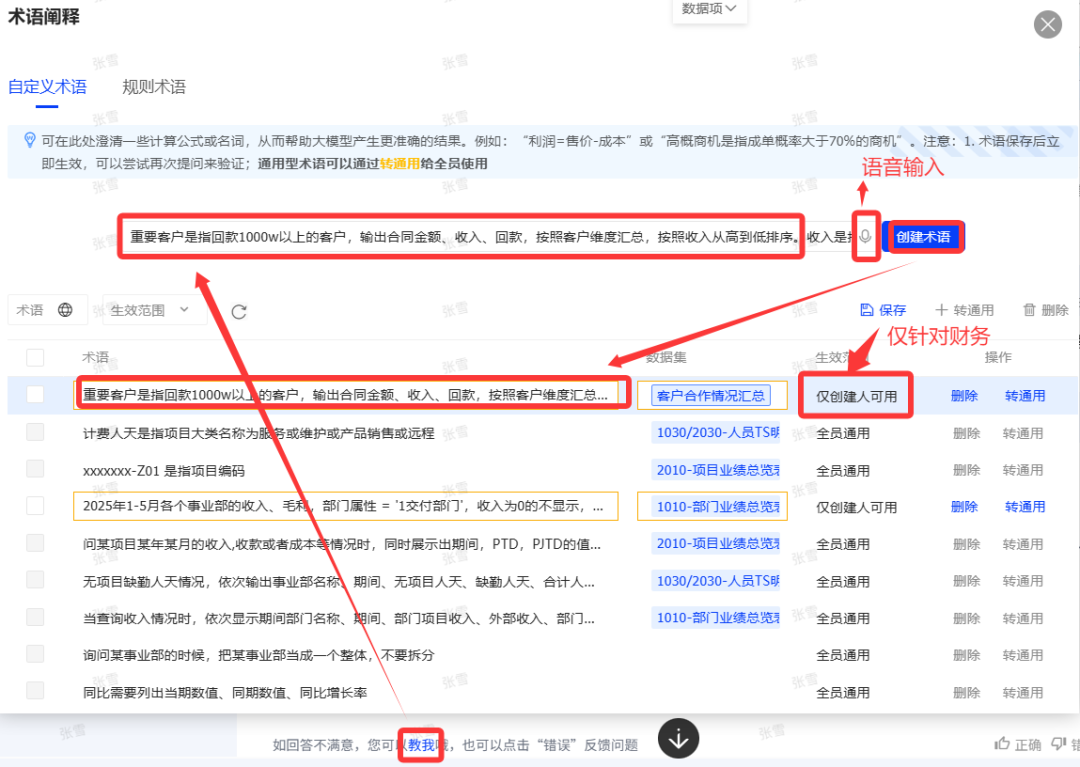
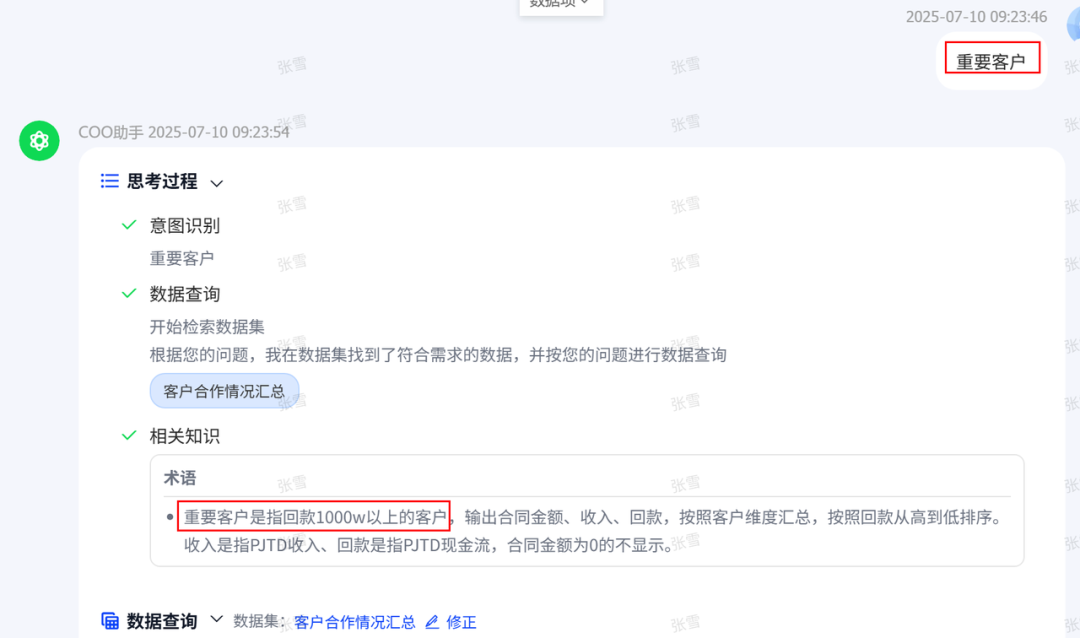
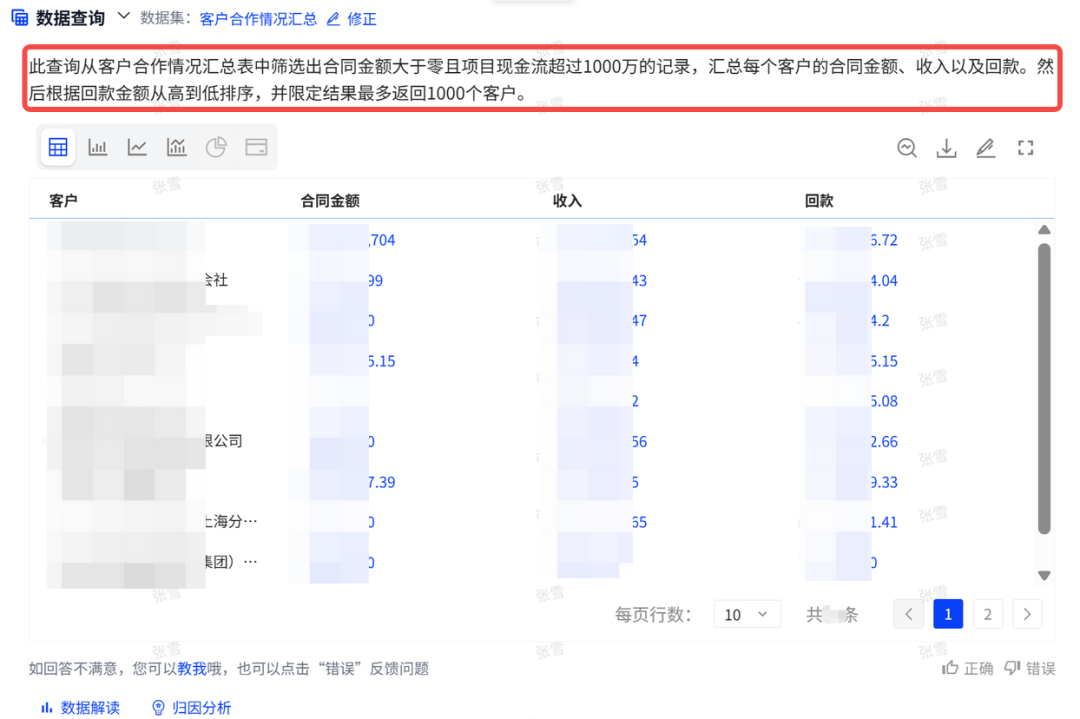
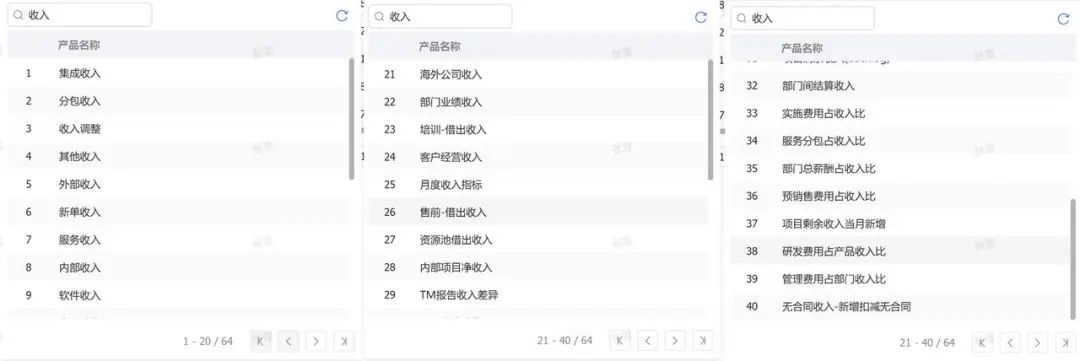
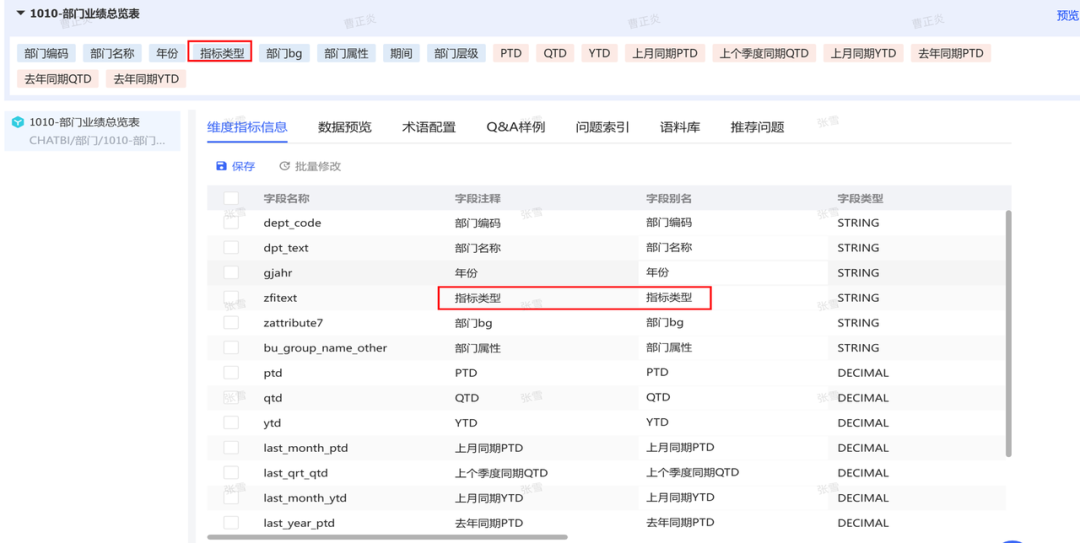
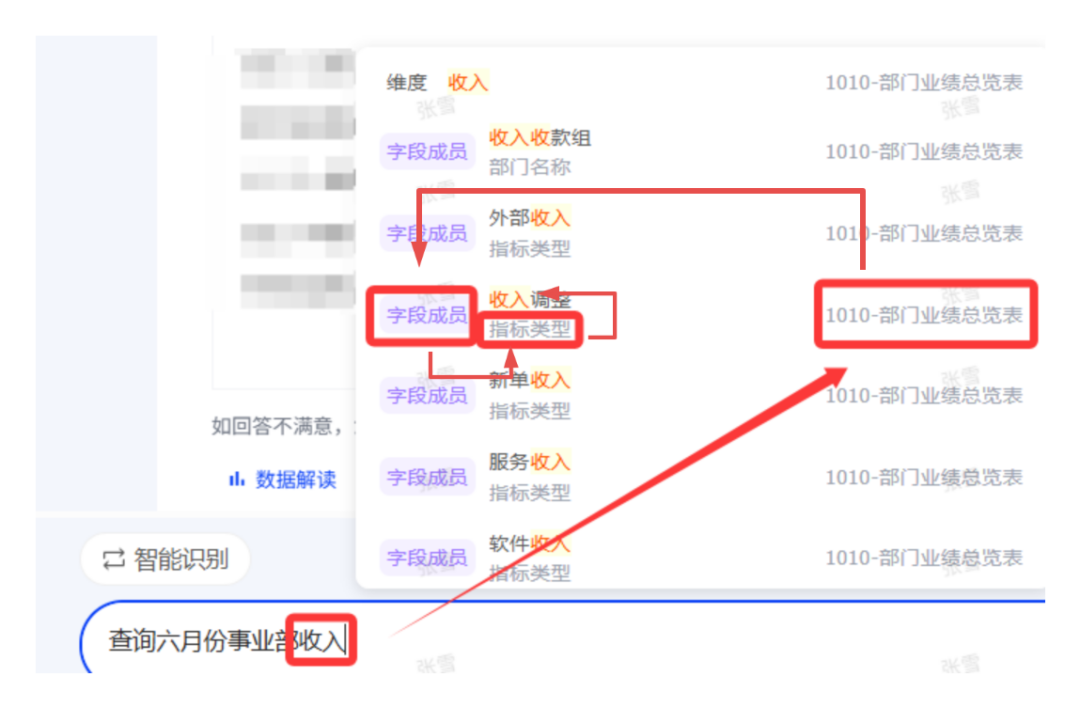
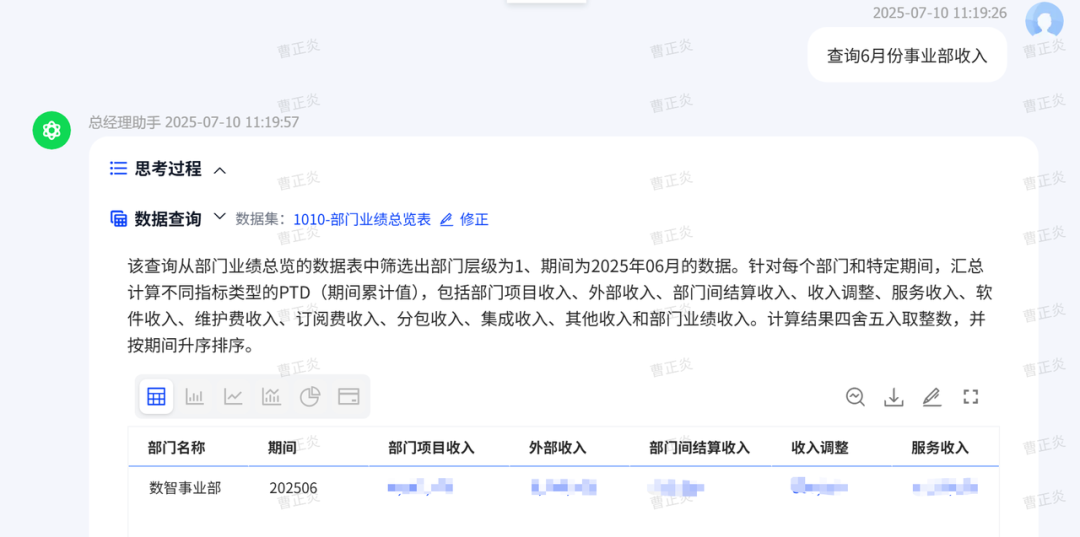
ChatBI问世以来,看得多,用得少。究其原因,担心答非所问,“乌纱帽”不保。「随时随地随心问」是AI问数能被普及的前置条件。 汉得ChatBI3.0重磅发布通过三大“黑科技”实现问数随心所欲,想问即问 启用私人调教模式:听懂“个人黑话” 💢 痛点: 每个企业有自己的“黑话”,每个人也有自己的“黑话”,企业的通用“黑话”可以通过提前训练解决,但个人的问数习惯和个人“黑话”往往成为ChatBI问数的拦路虎。 比如:“重要客户”,对销售而言是“收入最多的客户”,对财务而言是“回款最多的客户”,指望AI能自动“懂”每一个人的内心,是不可能的。 市面上的ChatBI问数产品基本上要靠IT后台定义,但IT无法穷举所有用户的想法,导致无法推给用户使用。 ✨ ChatBI 3.0怎么做? 启动私人“教我”模式:不需IT后台穷举处理,直接前端点击“教我”,支持语音输入进行调教。 销售调教:“重要客户是指收入1000w以上的客户” 财务调教:“重要客户是指回款1000W以上的客户” ✅ 一次调教,终身生效。忠诚聪明,越用越顺手。 ❌ 未调教模式下:“私人小秘书”理解不了,无法给出答案。 ✅ 调教后,以销售人员和财务人员为例: 💡 销售调教 << 滑动查看更多内容 >> 💡 财务调教 << 滑动查看更多内容 >> 启用语料训练模式:精准识别“每一个指标定义” 💢 痛点: ChatBI实际问数过程中,最令人头疼的就是相似的数据太多,人都难以识别,更不用说AI来智能识别。 以汉得的“收入”为例:指标口径就以高达64个。当事业部总经理问“收入”时,是想问部门项目收入、部门业绩收入、内部收入、外部收入,还是其他的收入呢?更难的是,各种收入指标不是以每一个指标作为一个字段,而是作为值存储在同一个字段里,AI识别,难上加难。 ✨ ChatBI 3.0怎么做? 边问边提示:在输入问题时,自动识别输入关键字,根据关键字自动提示相似指标和相似字段。 ✅ “妈妈再也不用担心我的学习”,自动识别,智能推荐,从“无所适从”到“随心使用”。 💡 以汉得的“收入”为例 << 滑动查看更多内容 >> 💡 “智能识别王”出场了 << 滑动查看更多内容 >> 启用NL2DSL新架构:快!准!稳! 💢 痛点: 常规架构下的ChatBI问数,大模型输出,极致性能也需要10s左右,使用起来不顺畅,效率也不高。 ✨ ChatBI 3.0怎么做? 意图理解使用自研小模型:基于命名实体识别,自研HNER,自动提取语料,智能识别。 输出处理使用SQL2DSL:SQL翻译、图表推荐无需使用大模型,更精准、更高效。 ✅ 问数效率从10s+提升到5s+,提效50%。 💡 新架构参考: 启用小模型:更准!更省! 💢 痛点: 基于DeepSeek或者Qwen3大模型私有化部署,基础投入动辄百万,成本望而生畏。 ✨ ChatBI 3.0怎么做? SQL生成使用SQL小模型:引入特定SQL优化场景的SQL小模型,仅需80G~160G显存,预算20~40w。 ✅ 从上百万投入到小几十万投入,80%的成本节约。 汉得ChatBI3.0携三大“黑科技”而来,无论是个人“黑话”难理解,还是指标多到分不清,又或是等待太久、成本太高,ChatBI3.0都给出了贴心解法。 我们希望汉得ChatBI3.0能够实实在在为正在使用问数的客户解决“麻烦事”,也为正在观望的企业打上“强心针”,让问数这件事变得简单又靠谱,真正做到“为工作助力,为企业增效”。 立即联系我们 解锁汉得ChatBI智能问数3.0 驶入「精准问数高速路」!











.jpg)
.jpg)






